Hyper-V Cluster Heartbeat for MDT ref VM goes bananas or?
I have been helping a customer with their environment and we had a problem that took me a while to figure out.
They were baking reference images for their SCCM environment and the best and easiest way is to use VM´s of course. The problem that occurred was that when the image was being transferred back to the MDT server the VM rebooted after half of the image had been uploaded….
So what was doing this crazy behavior? It took me a little while before I realized what it was all about and it had to do with the Hyper-V cluster platform and resilience and heartbeat functionality!
So at first the build VM boots from the MDT image, no integration tools yet then but then it restarts to install applications and stuff within the OS and as the customer works on a Windows 7 image you can see it starts to send heartbeat to the host.
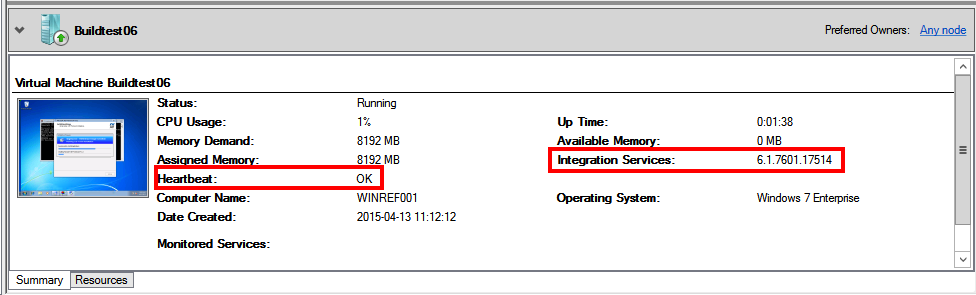
As you might know, clients and servers since Windows Vista and 2008 have integrational services by default in them although best practice is to upgrade them as soon as possible if the VM shall continue to reside in Hyper-V.
The interesting part in this case was that the OS rebooted within itself when it was finished with sysprep to start the MDT image for transferring the WIM back to the MDT server and the cluster/hyper-v did not notice this and thus it thought that the heartbeat stopped.
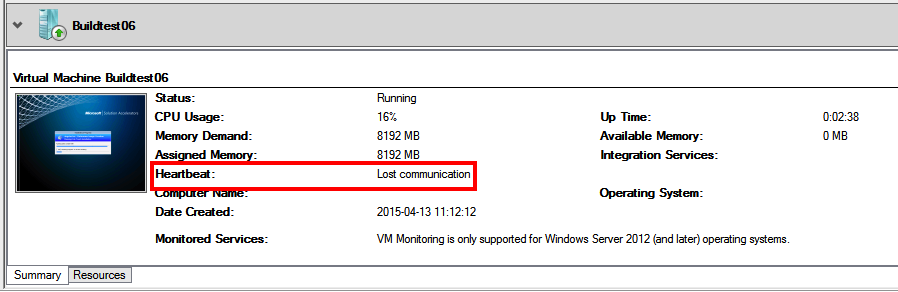
And as it was a cluster resource this heartbeat loss was handled by default, and guess what, rebooted!
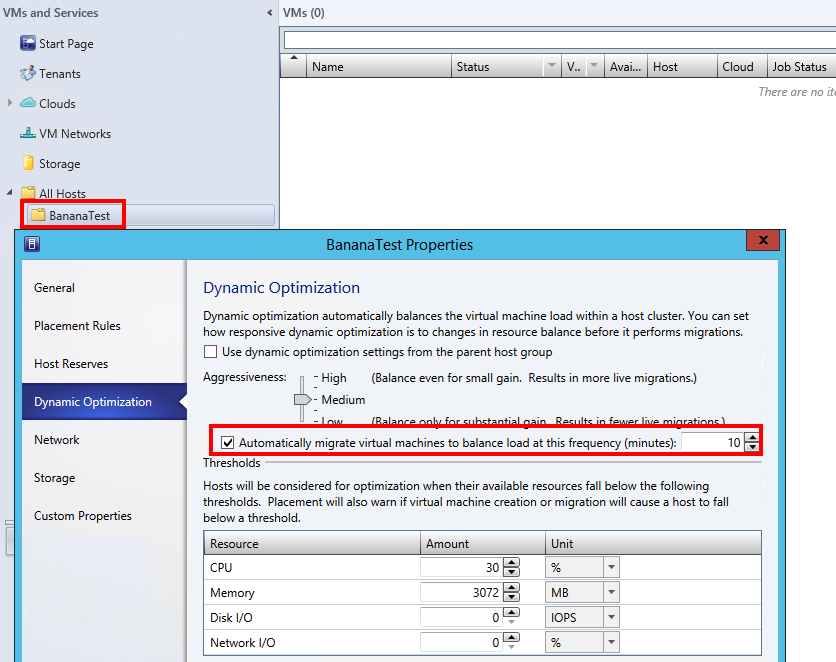
So what settings in the cluster resource does this madness? First of all, the Heartbeat setting on the cluster vm resource properties
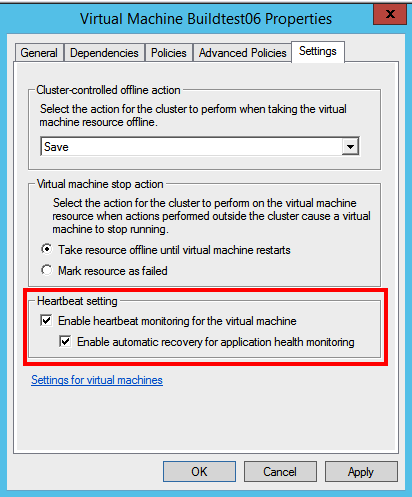
This can be read on the technet site about Heatbeat setting for Hyper-V clusters:

And then you have policy what the cluster should do after it thinks the vm has become unresponsive:
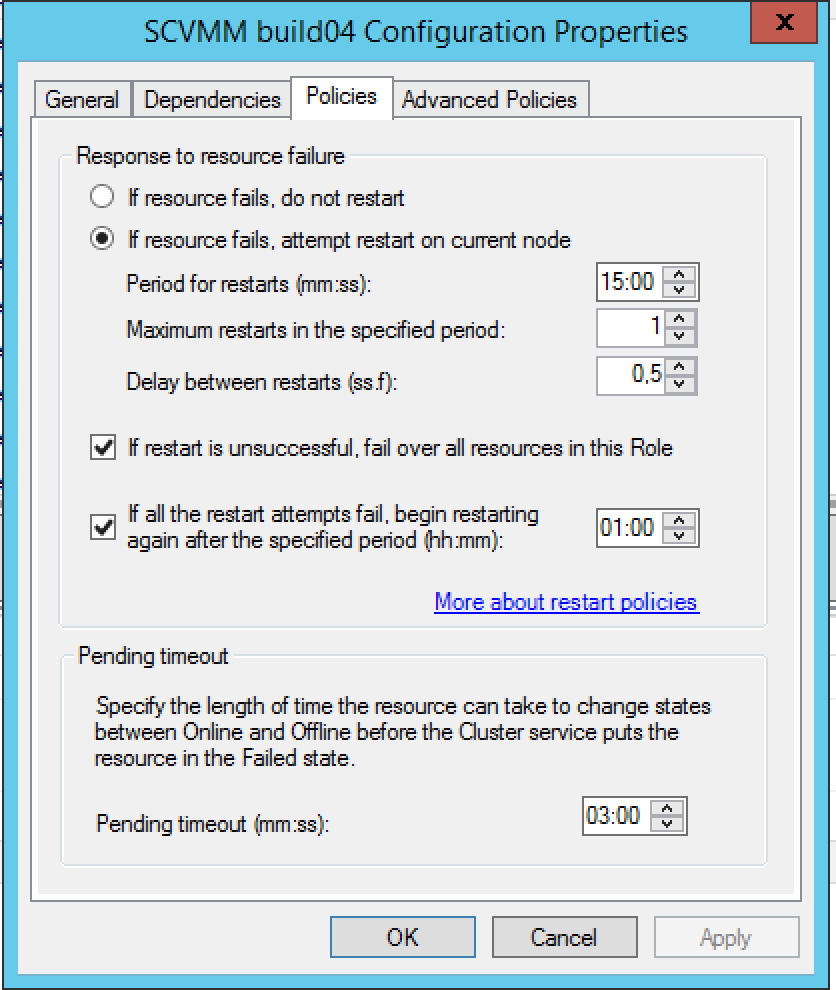
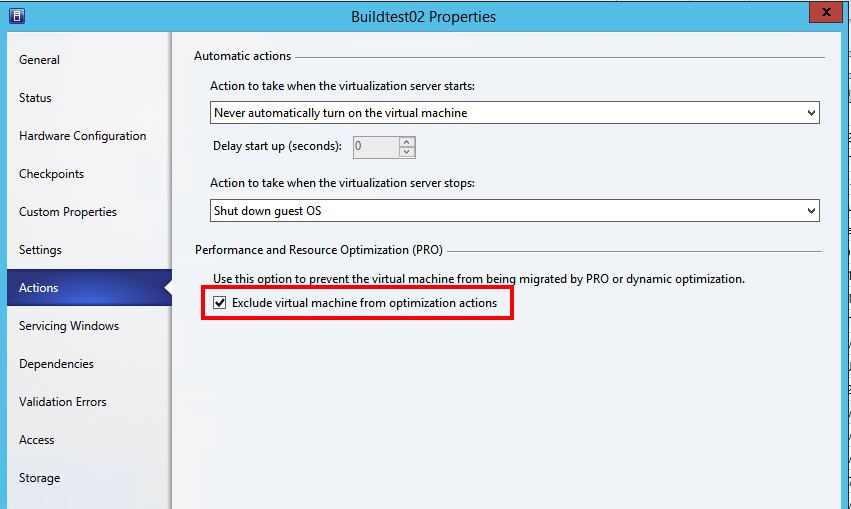
There are different ways to stop the cluster from rebooting the machine and one of them is to disable heartbeat check and another is to set the response to failure to do nothing,
The customer uses mostly VMM console and for them when building a new VM for MDT reference builds they can set the integrational services to disable heartbeat check and thus not get their work postponed by unwanted reboots.
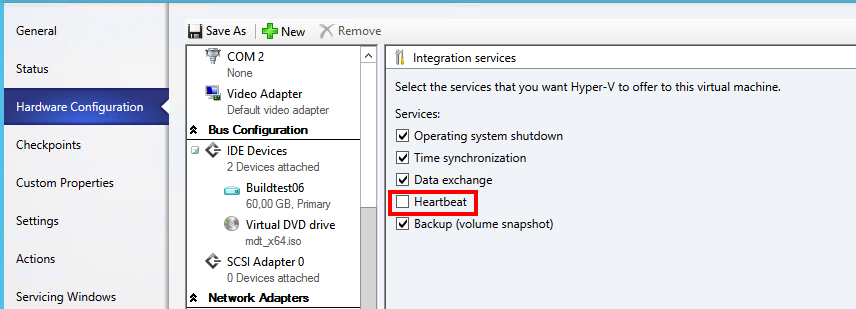
During the search for why I checked Host Nic drivers as I thought that it might have something with a transfer error but could not find anything, positively the hosts got up on the latest nic firmware and drivers 😉 . My suspicion that it had to be the cluster was awaken after I had spun up a test VM that was not part of the cluster and that one succeeded in the build and transfer.
This is a rare case and I would say that in 99% of the cases you want the default behaviour to happened as a VM can become unresponsive and then the cluster can try a reboot to regain into operations..
Clarification: If you spin up a VM with a OS or pxe image that does not have integrational services it will not reboot the VM after the cluster timeout, the OS has to start sending heartbeat to the Hyper-V host and then it will be under surveillance and managed by the cluster until properly shut down!
Hope that this helps for someone out there wondering what happens…